As an Engineering Manager, I forced AI-assisted coding on all three of my teams at the start of 2026. After one month, I ran a survey. The results surprised me.

AI Features — experimental
Summarize or translate this post using AI running entirely on your device. No data leaves your browser.
Requires Chrome with Built-in AI APIs enabled.
DISCLAIMER: I don’t see my engineers the way they’re depicted in the image above. But I loved how Nano Banana portrayed me so I decided to keep it anyway 😁
“You have to try it. No, seriously. Starting next week, everyone uses AI-assisted coding by default. That’s it.”
I said it in early January 2026, standing in front of my three software engineering teams. On LinkedIn I described myself as having “acted as an authoritarian manager”, jokingly. But I wasn’t joking that much 😁
I’ve been writing about how AI-assisted development changed my own coding habits, and about how AI became a bridge between ideas and execution. But there’s a difference between an Engineering Manager coding late on a Saturday and asking his team to change how they work every day. One is a personal experiment. The other is a management decision that affects real people, their craft, and their sense of autonomy.
So I put a number on it: one month. We’d run it as a forced experiment, then I’d ask for feedback and let the data speak.
Here’s what I discovered.
🤔 Why a Mandate Instead of a Recommendation?
I know what you might be thinking: mandates are authoritarian and engineers are professionals who should choose their own tools.
In principle I agree, but I saw “optional adoption” as too risky for the AI-assisted development wave.
I was worried that if I hadn’t acted, six months later I’d find a split culture, inconsistent practices and no shared learning.
The only way to have a genuine team opinion on something is for the whole team to actually experience it.
I wasn’t asking them to adopt it permanently. I was asking them to give it a real try, and I committed to listening. That seemed reasonable.
Twelve engineers completed the survey after one month. Here’s what they said.
🚀 Velocity: Everyone Moved Faster
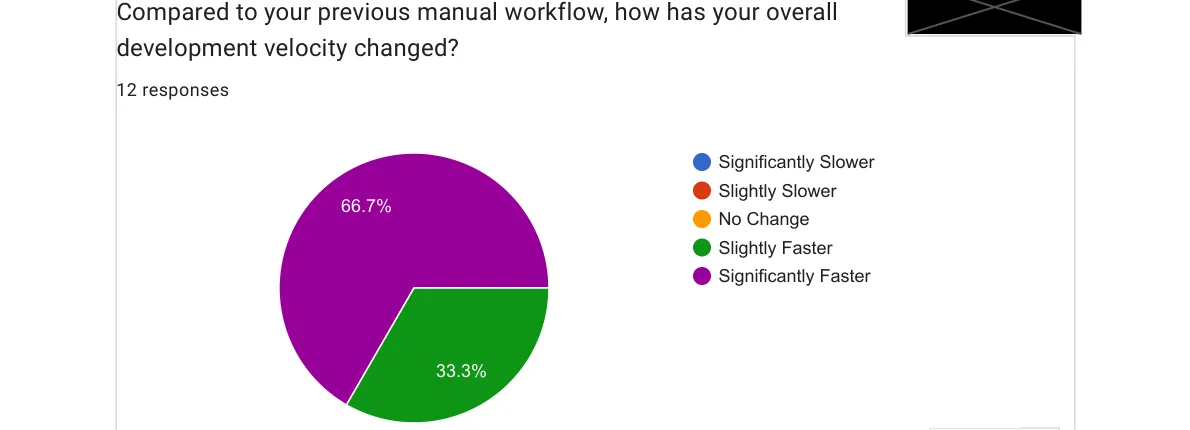
100% of the team perceived they moved faster. Nobody reported the same pace. Nobody reported slowing down.
I was not expecting unanimity. I expected a healthy distribution, maybe some skeptics who felt the review overhead cancelled out the generation speed. Instead: everyone, without exception, felt faster.
Again: I don’t have objective data to prove this claim, but for my purposes it was enough to have an impact on people’s perception.
🤨 Code Quality: Holding Steady, With Nuance
The velocity result would be pointless if quality had collapsed. Here’s what the team reported:
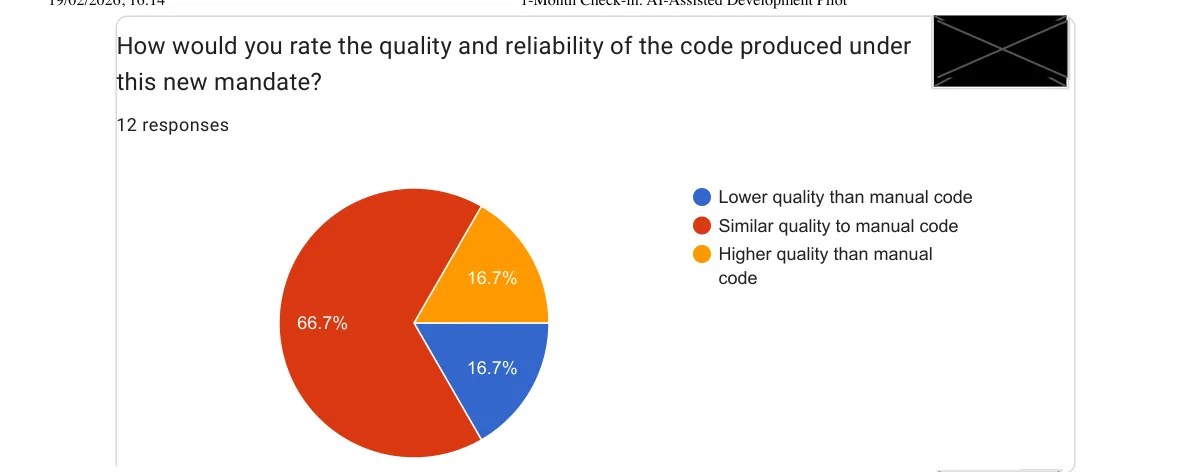
Two thirds see no quality regression. A sixth even reports improvements. One sixth report lower quality, which tells me the tool is not uniformly good in all contexts, or that some team members haven’t yet found the prompting approach that works for them.
This maps to something I said in my post on context engineering: the quality of the output depends heavily on how well context is provided. One of the open-ended responses from the survey said it directly:
“Results depend heavily on the prompting approach — we should share best practices as a team.”
That’s feedback I’m taking seriously. Shared tooling without shared technique is only half the picture.
⏱️ The Debug vs. Write Balance Shifted
Here’s the result that generated the most interesting conversation with my team:
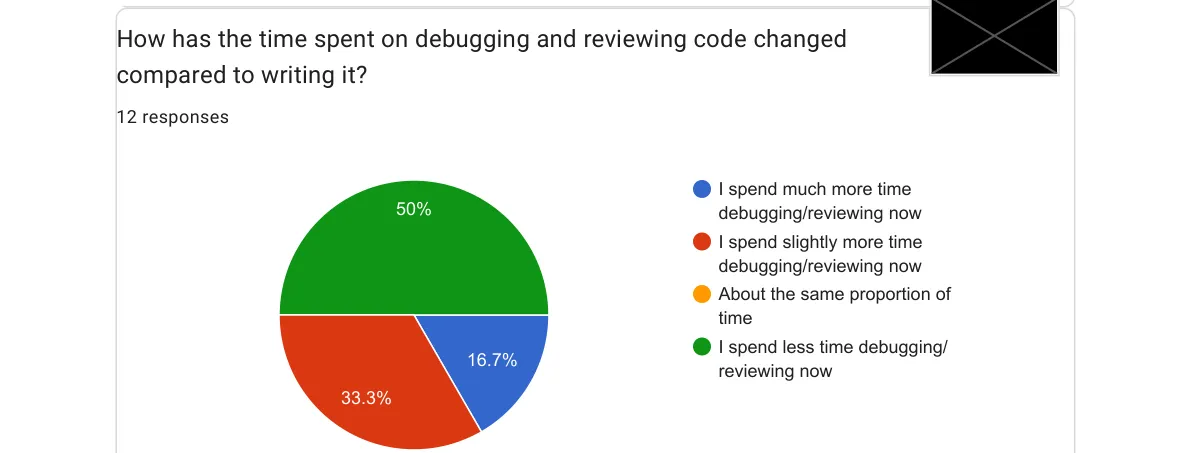
Half the team is spending more time reviewing AI output than they used to spend writing code themselves. That’s a real shift in the nature of the work. And honestly? I think it’s mostly healthy.
One of the survey responses put it in a way that stuck with me:
“Reviewing junior AI-generated code is a great learning opportunity. The code is ‘okay’ but lacks taste.”
That phrase, lacks taste, is exactly right. AI generates structurally correct code that often misses the subtle, accumulated judgment that comes from years of shipping software in a specific domain with a specific team. The code works. It just doesn’t always belong.
Which means we have another way to help less experienced people develop their judgment, through code review comments.
🛠️ Where AI Actually Helped
I asked the team which tasks they found AI most helpful for. They could select multiple options:
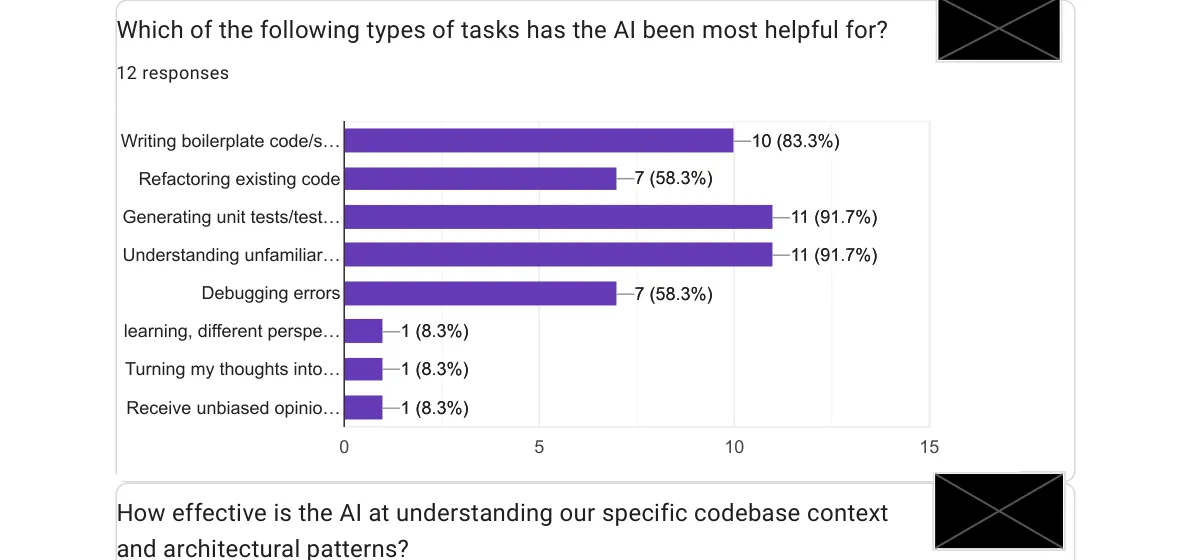
Two tasks tied at the top: generating unit tests and understanding unfamiliar code, both at nearly 92%.
The unit test result doesn’t surprise me. This is where AI consistently shines because tests are well-scoped, have clear success criteria, and free up developer time for the harder judgment calls. I’ve written about this before: asking the AI to write tests and then validating them is one of the best uses of the tool.
The “understanding unfamiliar code” result is the one that excites me most. We work on a Java monorepo with years of accumulated context. New joiners now use AI as a codebase navigator. A patient and always-available assistant. One respondent noted:
“It managed to make consistency checks across 4 repositories and refactored code in a good way.”
That said, another respondent added a caveat:
“It completely missed the purpose of the tests it created — I had to switch to ‘manual’ mode.”
It happens. AI needs to be able to hallucinate to remain such an effective tool.
🔍 How Well Does AI Actually Understand Our Codebase?
I asked the team to rate AI’s effectiveness at understanding our specific codebase on a 1-to-5 scale.
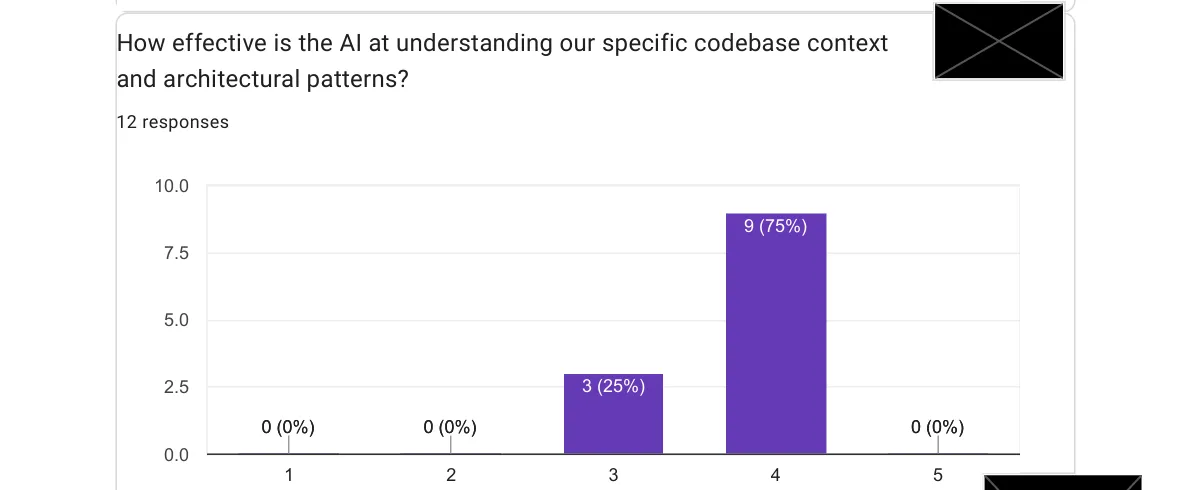
No one rated it below 4. That’s a meaningful signal, especially for a complex enterprise codebase. One respondent mentioned that Opus works great but is expensive on tokens, and that the IntelliJ integration still has rough edges. Tool maturity is still catching up to model capability.
The suggestion that came out of this: invest time in AGENTS.md, copilot-instructions.md, and CLAUDE.md tuning.
🔐 Security Trust: A Clear Gap
I asked the team to rate how much they trust AI-generated code from a security perspective, on a 1-to-5 scale.
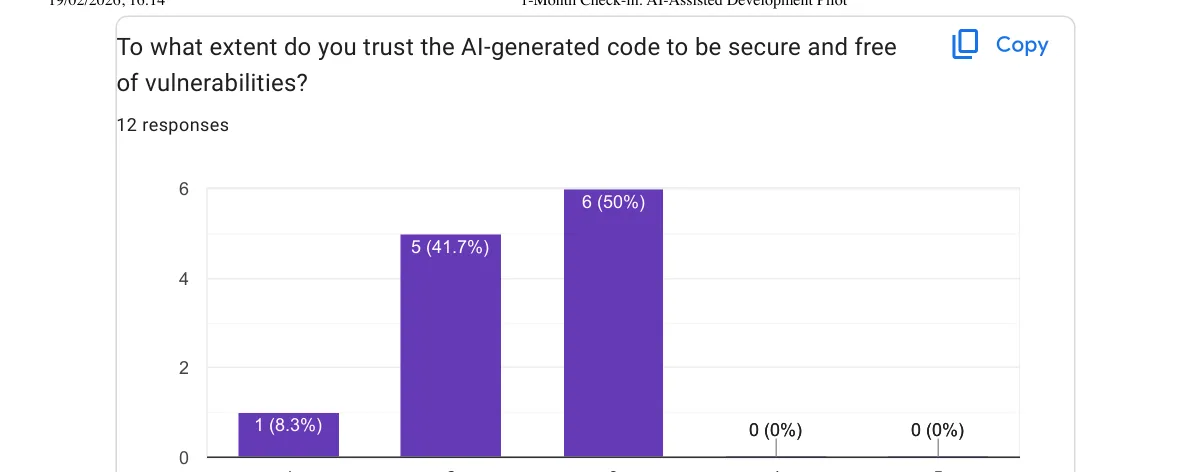
Nobody gave it higher than 3. The mean is somewhere around 2.4/5. Nobody on the team feels confident enough to ship AI-generated code without careful security scrutiny, and I think that’s exactly the right instinct. AI models don’t have threat models. They don’t think about your deployment environment, your user patterns or your data sensitivity. They produce code that works, not code that’s necessarily safe.
😌 The Result That Matters Most to Me
Here’s the one I keep coming back to. I asked: how do you feel at the end of the day compared to before?
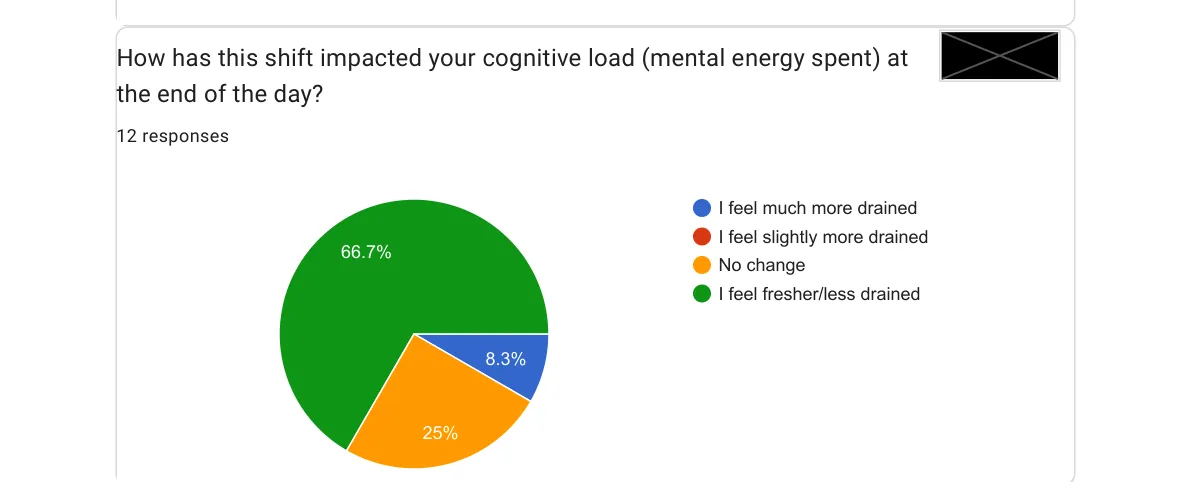
Two thirds of my team end the day less tired than they did before.
I’ve been a manager long enough to know that developer fatigue is a real cost, one that doesn’t show up in sprint velocity or ticket throughput. It shows up in the quality of decisions made. In the willingness to take on a hard problem on a Friday. In retention conversations six months later.
The idea that a change in tooling might reduce cognitive load, that technology can actually make the working day feel lighter, is what I find most exciting about this experiment. It aligns with something I genuinely believe:
Technology should serve human wellbeing, not just productivity metrics.
Velocity is good. Less drained engineers at the end of the day is better.
🔮 What the Team Wants Next
I asked: now that you’ve tried it, what’s your preference going forward?
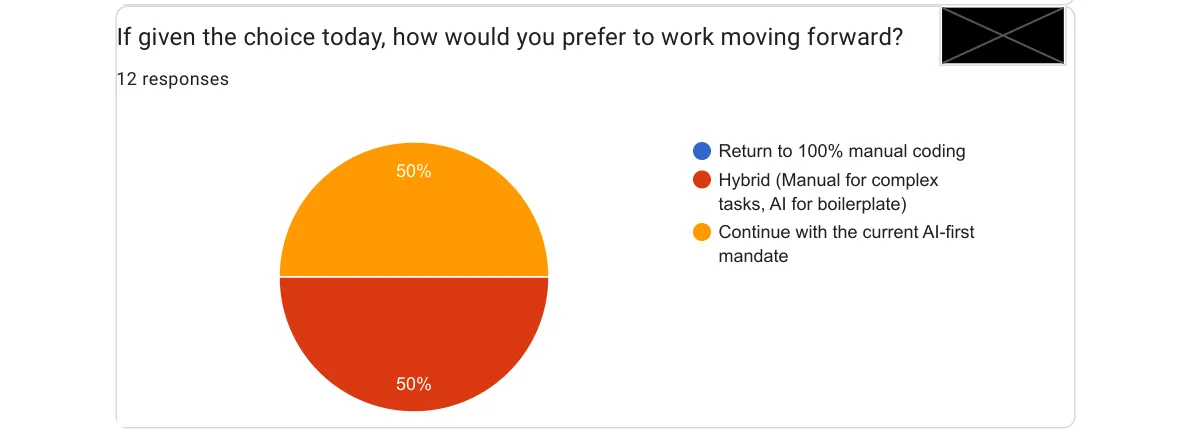
Zero people want to go back. That might be the clearest signal of all.
The split between “AI-first” and “hybrid” is healthy. It reflects different use cases and different comfort levels. My plan going forward is not to impose a single workflow, but to make the hybrid approach concrete: clear team guidelines on when to lean on AI heavily, when to write manually, and how to review AI output with the right level of scrutiny.
One respondent asked specifically for concrete demos of AI workflow using our actual tools: the Java monorepo, our IDE setup. That’s going on the team agenda. Shared technique is table stakes for shared tooling.
💡 What I’m Taking Home
Twelve engineers. One month. A few things I now believe more firmly than before:
The productivity gains are real. 100% velocity improvement perception is not a rounding error. Something meaningful is happening.
The fatigue reduction is the underrated story. Velocity is measurable. Wellbeing is harder to quantify, but the signal here is strong. I want to track this over time.
The security gap needs a structured answer. Specific agents dedicated to reviewing this aspect?
Conclusion 🔁
I mandated AI. I listened to the feedback. I was surprised by what came back.
This was never about forcing a tool on engineers who didn’t want it. It was about giving everyone the same real experience before forming an opinion, and then building a shared practice from what we learned together.
The experiment worked. Not so much for the survey numbers, but because we now have a team with shared vocabulary, shared data, and shared next steps. That’s what a management decision should produce.
If you’re an Engineering Manager sitting on the fence: the tool is mature enough. The real question is whether you’re ready to lead the adoption with the same care you’d give any other team practice.